 LinMao's Blog(林茂的博客)
LinMao's Blog(林茂的博客)CUDA编程结构
CPU-GPU设备分成主机和设备:主机:CPU及其内存(主机内存),设备:GPU及其内存(设备内存)。CUDA编程模型有两个特色功能,一是通过一种层次结构来组织内存,二是通过层次结构来组织线程的访问。
从CUDA 6.0开始,NVIDIA提出了名为“统一寻址”(Unified Memory)的编程模型的改进,它连接了主机内存和设备内存空间,可使用单个指针访问CPU和GPU内存,无须彼此之间手动拷贝数据。
CUDA编译过程
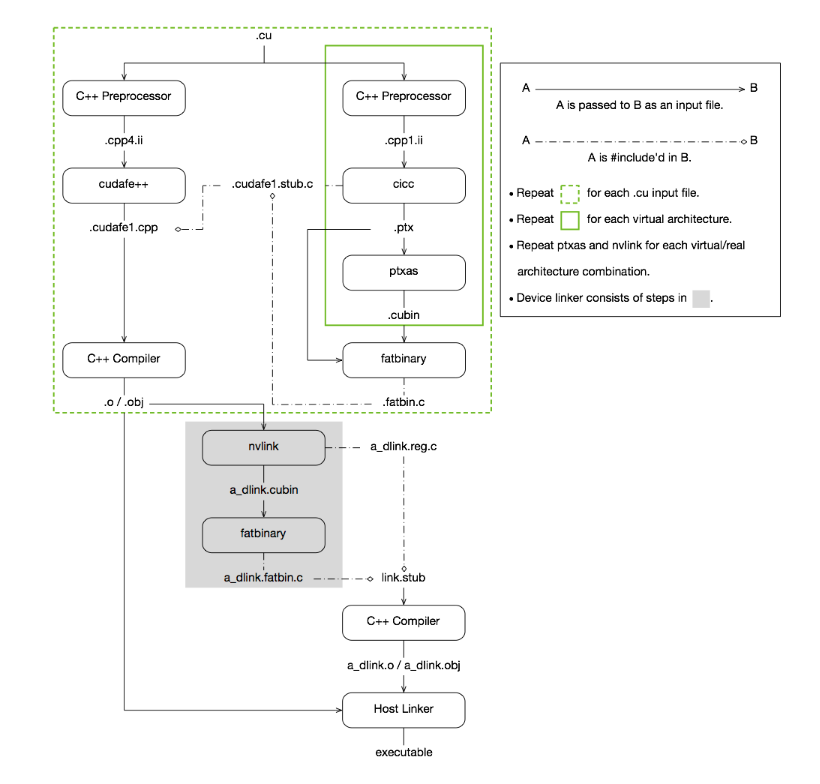
cuda编译过程如图。详见CUDA NVCC。
NVCC编译
NVCC通过两阶段编译模型来保证程序与不同代GPU的兼容性。每个阶段针对不同的GPU架构:虚拟架构和真实架构:虚拟架构确定编译成的代号的功能,真实架构确定编译成的真实代号的功能和性能。使用虚拟架构生成PTX中间文件,虚拟框架由compute_开头。虚拟架构通常是从大的GPU代上控制的,真实框架必须大于等于虚拟框架,真实框架对应真正运行的GPU,即编译阶段就确定要运行的GPU是什么。真实框架由sm_开头。
两种提高兼容性的方式:
即时编译(Just-In-Time):先编译程PTX中间文件,然后在执行的时候完成第二阶段的编译工作,缺点是增加了启动延时;
Fatbinaries:第二阶段生成多个版本的真是架构的二进制结果(cubin),然后运行时根据具体的真实架构来选择对应的二进制文件。
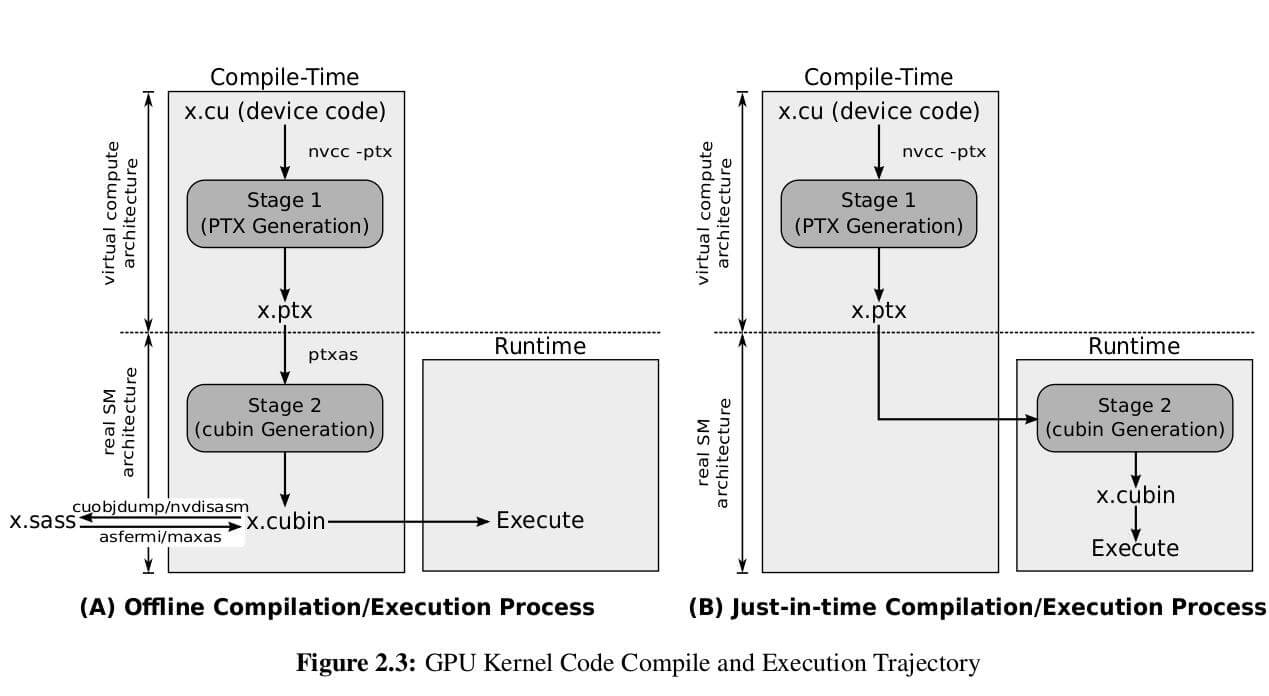
PTX 是并行线程执行( Parallel-Thread-Execution),是一个中间级的汇编代码。是预编译后GPU代码的一种形式,可以通过编译选项 “-keep”选择 输出PTX代码,当然也可以直接编写PTX级代码。 PTX是独立于gpu架构的,因此可以重用相同的代码适用于不同的GPU架构。而cubin二进制则已经指定了架构。Shader-Assembly (SASS),真正的机器汇编,由cubin文件经过cuobjdump工具转换而来。目前没有官方的sass to cubin的工具。
内存管理
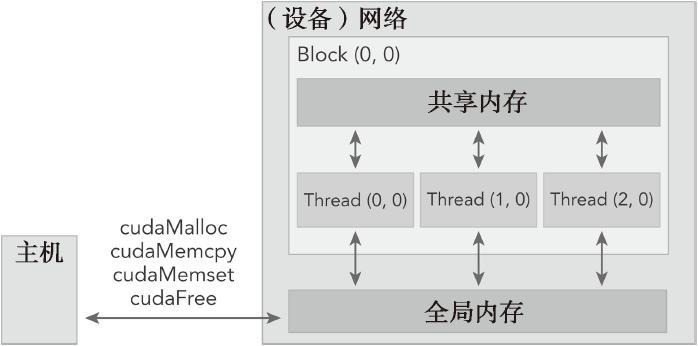
与CPU编程不同,GPU中的各级缓存以及各种内存是可以软件控制的,在编程时我们可以手动指定变量存储的位置。具体而言,这些内存包括寄存器、共享内存、常量内存、全局内存等。
CUDA中操作GPU内存的函数有:cudaMalloc, cudaMemcpy, cudaMemset, cudaFree;依次与C语言中的相关内存操作函数(malloc, memcpy, memset, free)的功能相对应。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
// 给设备分配初值 cudaError_t cudaMalloc(void** devPtr, size_t size); // 给设备内存上设置某个初值 cudaError_t cudaMemset( void* devPtr, int value, size_t count ); // 释放设备上的空间 cudaError_t cudaFree( void* devPtr ); // 在设备和主机之间复制数据 cudaError_t cudaMemcpy(void* dst, const void* src, size_t cout, cudaMemcpyKind kind) |
cudaError_t cudaMemcpy(void* dst, const void* src, size_t cout, cudaMemcpyKind kind)
该函数负责主机和设备之间的数据传输,从src指向的源存储区复制一定数量的字节到dst指向的目标
存储区。复制方向由kind指定,其中的kind有以下几种:
cudaMemcpyHostToHostcudaMemcpyHostToDevicecudaMemcpyDeviceToHostcudaMemcpyDeviceToDevice
该函数以同步方式执行,因为在cudaMemcpy函数返回以及传输操作完成之前主机应用程序是阻塞的。除了内核启动之外的CUDA调用都会返回一个错误的枚举类型cuda Error_t。如果GPU内存分配成功,函数返回cudaSuccess,否则返回cudaErrorMemoryAllocation。
可以用CUDA运行时函数将错误代码转化为可读的错误消息:
|
1 2 3 |
char* cudaGetErrorString(cudaError_t error); // cudaGetErrorString函数和C语言中的strerror函数类似。 |
CUDA编程模型最显著的一个特点就是揭示了内存层次结构。在GPU内存层次结构中,最主要的两种内存是全局内存和共享内存。全局类似于CPU的系统内存,而共享内存类似于CPU的缓存。然而GPU的共享内存可以由CUDA C的内核直接控制。简化的CUDA内存编程模型:
线程管理
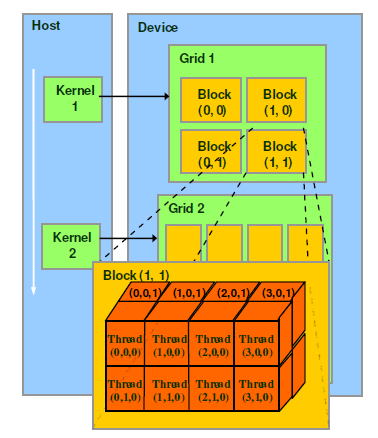
由一个内核启动所产生的所有线程统称为一个网格(grid)。同一网格中的所有线程共享相同的全局内存空间。一个网格由多个线程块(block)构成,一个线程块包含一组线程(thread),同一线程块内的线程协作可以通过以下方式来实现:同步和共享内存。不同的块内的线程不能协作。
线程靠一下两个坐标量区分:blockIdx(表示线程块在网格中的索引)和threadIdx(表示块内线程索引)。这两个变量都是三维变量dim3类型,该坐标变量是基于uint3定义的CUDA内置的向量类型,是一个包含3个无符号整数的结构,可以通过x、y、z三个字段来指定。
网格和块的维度由下列两个内置变量指定:blockDim(线程块的维度,用每个线程块中的线程数来表示)和gridDim(线程格的维度,用每个线程格中的线程数来表示)。它们是dim3类型的变量,是基于uint3定义的整数型向量,用来表示维度,所有未指定的元素都被初始化为1。
通常,一个线程格会被组织成线程块的二维数组形式,一个线程块会被组织成线程的三维数组形式。
网格(Grid)、线程块(Block)和线程(Thread)的组织关系
CUDA的软件架构由网格(Grid)、线程块(Block)和线程(Thread)组成,相当于把GPU上的计算单元分为若干(2~3)个网格,每个网格内包含若干(最多65535)个线程块,每个线程块包含若干(最多512)个线程,三者的关系如下图:
thread,block,grid,warp是CUDA编程上的概念,以方便程序员软件设计,组织线程:
thread:一个CUDA的并行程序会被以许多个threads来执行。
block(CTA):数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。
grid:多个blocks则会再构成grid。
warp:GPU执行程序时的调度单位,目前cuda的warp的大小为32,同在一个warp的线程,以不同数据资源执行相同的指令,这就是所谓 SIMT。
CUDA编程
调用CUDA核函数
CUDA内核调用是对C语言函数调用语句的延伸,<<<>>>运算符内是核函数的执行配置。CUDA核函数调用格式如下:
|
1 2 3 4 |
kernel_name <<<grid, block>>>(argument list); // grid维度,表示线程块的数量 // block维度,表示线程的数量 |
通过函数调用时的执行配置,可以指定内核中线程数目与线程布局,同一个块内的线程可以相互协作,不同块内的线程不能相互协作。
编写CUDA核函数
一个使用__global__函数限定来定义的核函数:
|
1 2 3 |
# 核函数必须有一个void返回类型 __global__ void kernel_name(argument list); |
函数类型限定符指定一个函数在主机上执行还是在设备上执行,以及可被主机调用还是被设备调用。CUDA函数类型限定符有:
| 限定符 | 执行 | 调用 | 备注 |
|---|---|---|---|
__global__ |
在设备端执行 | 从主机端调用,也可从算理为3的设备中调用 | 必须有一个void返回类型 |
__device__ |
在设备端执行 | 仅能从设备端调用 | |
__host__ |
在主机端执行 | 仅能从主机端调用 | 可以省略 |
__device__和__host__限定符可以一齐使用,这样函数可以同时在主机和设备端进行编译。
CUDA核函数有以下限制(适用于所有核函数):
- 只能访问设备内存
- 必须具有void返回类型
- 不支持可变数量的参数
- 不支持静态变量
- 显示异步行为
异步调用
由于核函数调用与主机端程序是异步的,需要用cudaDeviceSynchronize函数来等待所有的GPU线程运行结束。
计时
CUDA5.0以后,NVIDIA提供了一个名为nvprof的命令行分析工具,可以帮助从应用程序的CPU和GPU活动情况中获取时间线信息,其包括内核执行、内存传输以及CUDA API的调用。用法如下:
|
1 2 |
nvprof [nvprof_args] <application> [application_args] |
设备信息
CUDA运行时API函数
|
1 2 |
cudaError_t cudaGetDeviceProperties(cudaDeviceProp* pop, int device); |
cudaDeviceProp结构体返回GPU设备的属性,可以通过以下网址查:https://docs.nvidia.com/cuda/cuda-runtime-api/structcudaDeviceProp.html#structcudaDeviceProp。
nvidia-smi命令
nvidia-smi是一个命令行工具,用于管理和监控GPU设备,并允许查询和修改设备状态。
在运行时设置设备
支持多GPU的系统是很常见的。对于一个有N个GPU的系统,nvidia-smi从0到N―1标记设备ID。使用环境变量
CUDA_VISIBLE_DEVICES就可以在运行时指定所选的GPU且无须更改应用程序。设置运行时环境变量CUDA_VISIBLE_DEVICES=2。nvidia驱动程序会屏蔽其他GPU,这时设备2作为设备0出现在应用程序中。也可以使用CUDA_VISIBLE_DEVICES指定多个设备。例如,如果想测试GPU 2和GPU 3,可以设置CUDA_VISIBLE_DEVICES=2, 3。然后,在运行时,nvidia驱动程序将只使用ID为2和3的设备,并且会将设备ID分别映射为0和1。
Reference:


最新评论
感谢博主,让我PyTorch入了门!
博主你好,今晚我们下馆子不?
博主,你的博客用的哪家的服务器。
您好,请问您对QNN-MO-PYNQ这个项目有研究吗?想请问如何去训练自己的数据集从而实现新的目标检测呢?
where is the source code ? bomb1 188 2 8 0 0 hello world 0 0 0 0 0 0 1 1 9?5
在安装qemu的过程中,一定在make install 前加入 sudo赋予权限。
所以作者你是训练的tiny-yolov3还是yolov3...
很有用