 LinMao's Blog(林茂的博客)
LinMao's Blog(林茂的博客)GPU简介
GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,因此当我们在说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device)
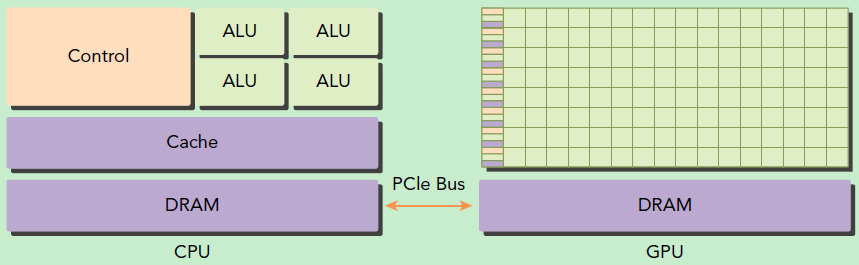
一个典型的计算流程
- 分配GPU内存
- 将数据从 CPU 的内存拷贝到 GPU 的内存
- 调用CUDA内核完成计算(CPU 把计算指令传送给 GPU,GPU 把计算任务分配到各个 CUDA core 并行处理,计算结果写到 GPU 内存里)
- , 将GPU内存计算结果拷贝到 CPU 内存里
- 释放GPU内存
GPU的性能指标
把GPU计算过程比作船运效率,船运效率与轮船航行速度、轮船吨位、装卸货时间和港口等待时间等等,GPU的性能指标:
- 芯片时钟周期:芯片主频越高始终周期就越低,速度越快;类似于轮船的航行速度
- CUDA cores:并行计算的核心处理器数目;类似于轮船的吨位
- 内存(显存)大小:类似港口大小
- 内存带宽(显存带宽,Bandwidth):数据传输速度;类似于轮船装卸货速度
- CPU/GPU之间通讯带宽:类似从卡车到港口上的装卸货速度
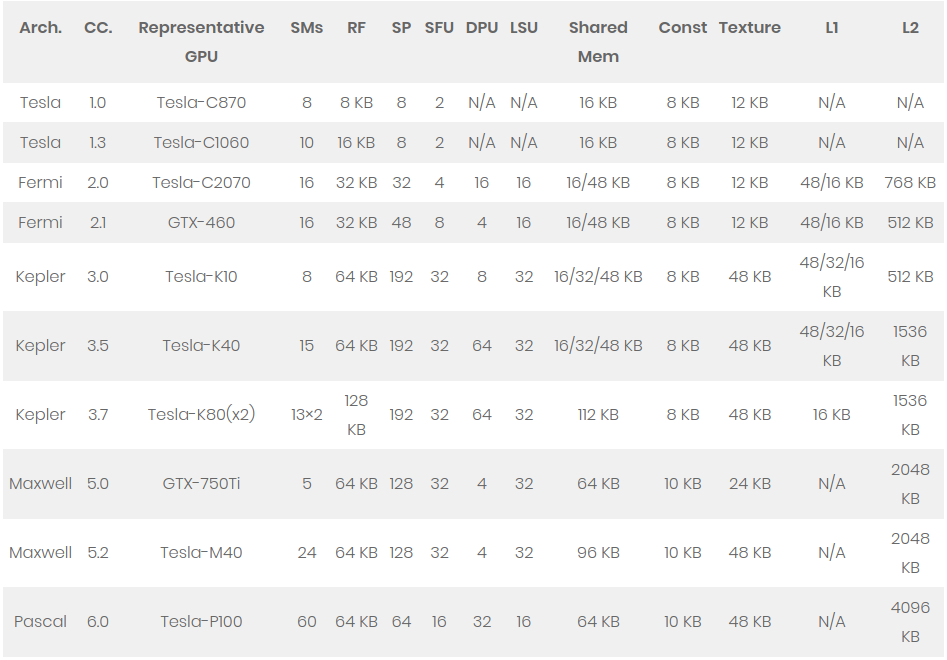
GPU架构历史
| Arch. | Release Year | Compute Capability | Process | Most highlighted Features | Flagship GTX/Tesla/Jetson GPUS |
|---|---|---|---|---|---|
| Tesla | 2008 | 1.0, 1.1, 1.2, 1.3 | 65 nm | GPU baseline architecture | GTX8800, GTX9800, GTX280,Tesla1060 |
| Fermi | 2010 | 2.0, 2.1 | 40 nm | L1/L2 caches, dual scheduler | GTX480, GTX460, GTX580,Tesla2070 |
| Kepler | 2012 | 3.0, 3.2, 3.5, 3.7 | 40/28 nm | Floating-point performance | GTX680, GTX-TitanZ, Tesla-K10,Tesla-K20, Tesla-K40, Tesla-K80,Jetson-TK1 |
| Maxwell | 2014 | 5.0, 5.2, 5.3 | 28 nm | Power efficiency | GTX750Ti, GTX980, GTX-TitanX,Tesla-M40, Tesla-M60, Jetson-TX1 |
| Pascal | 2016 | 6.0, 6.1, 6.2 | 16 nm | 3D Memory, numeric SMs | Tesla-GP100, GTX1080 |
| Volta | 2017 | 7.0, 7.2 | RT Core 的专用光线追踪处理器 | 专业显卡GV100、V100 | |
| Turing | 2018 | 7.5 | NVIDIA GeForce 20系列 | ||
| Ampere | 2020 | 8.0, 8.6 | 7, 8nm | NVIDIA GeForce 30系列 |
运算和存储结构
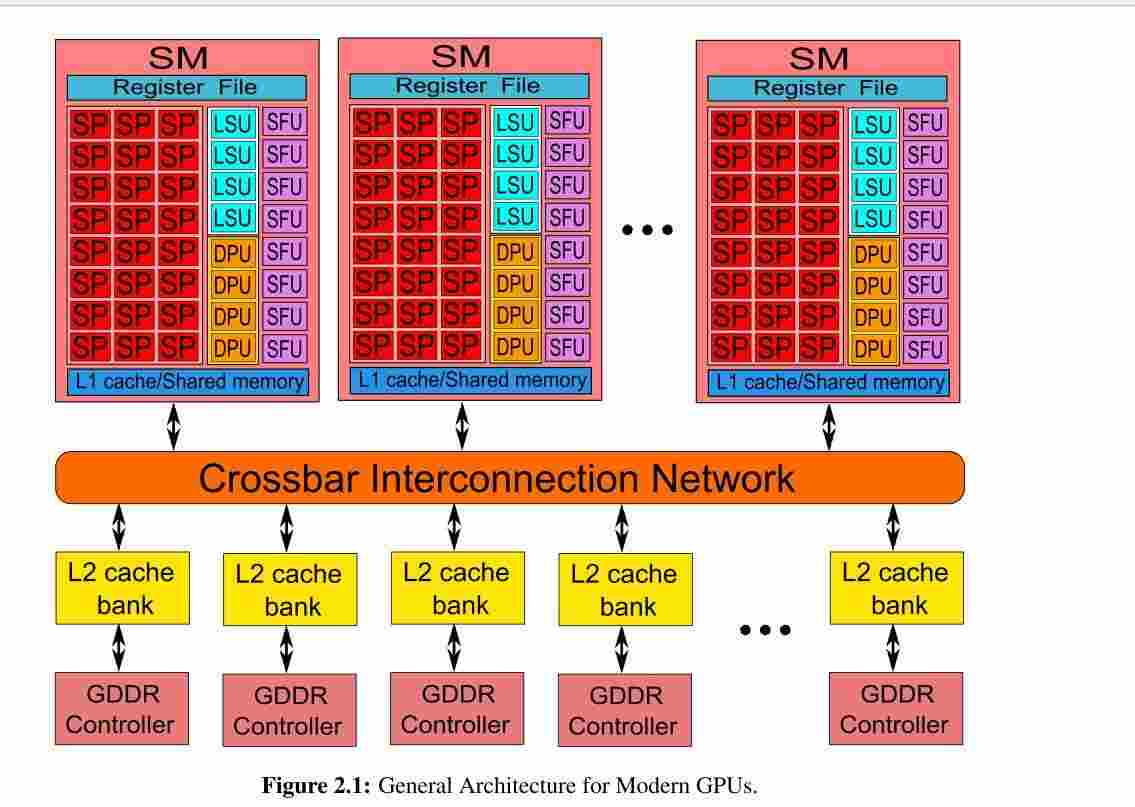
GPU由多个streaming-multiprocessors (SMs)组成,它们通过crossbar内部互联网络共享L2 Cache和DRAM控制器。一个SM包含多个scalar processor cores (SPs) 和两种其他类型的功能单元:Double-Precision Units (DPUs) 用来双精度浮点数计算; Special-Function Units (SFUs)来处理超越函数和纹理获取的插值,还包含register files (RFs), load- store units (LSUs), scratchpad memory (i.e., shared memory), 以及用于片上缓存的各种 caches (i.e., instruction cache, constant cache, texture/read-only cache, L1 cache) 。
功能单元
Scalar-Processor (SP): SM的主要基础处理器,实现基本的整数、浮点数计算,比较和类型转换等操作。每个SP包含一个单精度浮点数处理单元FPU和一个整数算数/逻辑单元ALU。
Special-Function-Unit (SFU): SFU实现了快速透明的函数计算(sin,cos等)和平面属性插值。
Double-Precision-Unit (DPU): 专门的双精度计算单元。
Load-Store-Unit (LSU):从内存读写数据的单元。包含独立的计算单元来快速计算内存请求的源和目的地址。
设备内存
| Memory | On/Off Chip | Cached | Access | Scope | Lifetime |
|---|---|---|---|---|---|
| Register Files | On | N/A | Read/Write | Per-thread | Thread |
| Local Memory | Off | L1/L2 | Read/Write | Per-thread | Thread |
| Shared Memory | On | N/A | Read/Write | Thread Block(CTA) | Tread Block(CTA) |
| Global Memory | Off | L1/L2 | Read/Write | GPU+CPU | Host Allocation |
| Constant Memory | Off | Constant cache | Read Only | GPU+CPU | Host Allocation |
| Texture Memory | Off | Texture cache | Read Only | GPU+CPU | Host Allocation |
Register Files (RF): 寄存器时线程私有的。GPU的寄存器很大,出于吞吐量的考虑,划分成banks。因此相比于CPU寄存器,GPU寄存器的latency更大,而且有更多潜在的bank conflicts。如果线程使用超过硬件限制的寄存器,则使用local memory来代替多占用的寄存器。
Local Memory (LM): 线程私有的。local memory不是物理空间,而是global memory的一部分,所以延时较大。它是线程私有的,主要用来临时的spilling,比如寄存器溢出,或者数组在Kernel里声明了,但编译器无法获得他准确的indexing。Local memory在Fremi和Kepler中可以被L1和L2 cached,但是在Maxwell和Pascal中只能被L2 cached。寄存器溢出到local memory会造成巨大的性能下降(引起了更多的指令和内存拥挤)尤其是cache miss时。
Shared Memory (HM,SMEM): 线程块中所有的线程共有,持续线程块的整个生命周期。又称为scratchpad memory,是片上的存储,SM里的所有单元共享。它可以用来作为同一个thread blocks里不同线程之间快速数据交换的通讯接口。由于是片上存储,带宽很大,访问延迟很小。因此,把global/local memory的访问迁移到SMEM上的优化是被编程手册推荐的。为了获得更高的带宽,SMEM被划分成banks,这样就可以并行的访问(寄存器文件和L2 cache也类似)。但是如果在一次内存请求中,访问的两个地址落在了同一个bank,就造成了bank conflict,此时请求需要串行化,从而降低了SMEM的性能。
Global Memory (GM): 所有线程都可访问。又称device memory,GPU片下内存,GPU主存。它是GPU性能的主要瓶颈。GM可达到的吞吐量取决于:(1)GM物理带宽限制,即pin数、线长度和DRAM的物理特性。因此在kelper以前增长缓慢,但是Pascal使用了3D栈内存技术,性能获得了巨大提升。(2) 访存请求合并。LSU一开始会计算每个warp的目标地址。在memory fetch之前,有一个特殊的地址合并硬件来检查同一个warp里地址是否是连续分布的。
Constant Memory (CM) / Constant Cache: 所有线程可访问且只读。常量内存用来存储在Kernel执行期间没有改变的数据。在所有GPU上都是64KB的off-chip。和local memory类似,都是Global memory的一部分。不被L1或L2 cached,有专门的constant cache。每个SM上8/10KB的常量cache被专门设计,以便单个内存地址的数据可以在同一时间广播给整个经线的所有线程。线程束中的线程每读一次,都会广播给线程束中其它线程。
Texture Memory (TM) / Texture Cache: 所有线程可访问且只读。又称surface memory也在全局内存上。被texture cache cached。Texture cache针对2D的空间局部性进行了优化。
每个线程都有独立的寄存器和Local Memory,同一个block的所有线程共享一个Shared Memory;Global Memory、Constantm Memory和Texture Memory是所有线程都可以访问的。Global Memory、Constantm Memory和Texture Memory对程序优化有特殊作用。
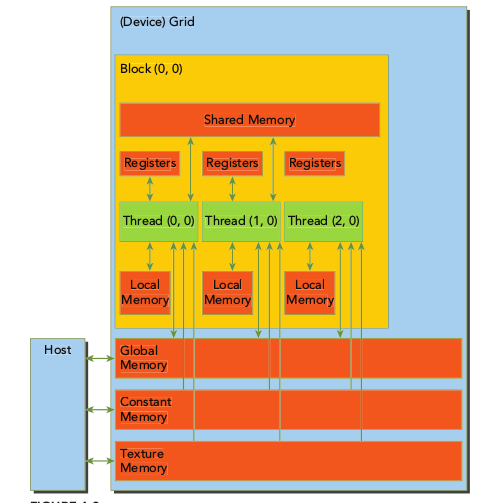
设备缓存
L1 Data-Cache:在Fermi上首次被提出来。SM的私有L1 Cache和SMEM共享片上存储,他们的大小是可以配置的,Fermi上16/48 or 48/16,Kepler上32/32 or 48/16。L1 cache line是128B。L1 data cache缓存global memory读和local memory的读写,并且是non-corherent。local memory主要用来寄存器溢出、函数调用和自动变量。当L1 cache 被用来缓存global memory时是只读的,当被用来缓存local memory时也是可写的。从Maxwell开始,传统的L1 cache被统一到了Texture cache里。
L2 Cache: 它被用来缓存各种类型的memory access
Interconnection Network (NC): crossbar network.它允许多个SM和L2 banks之间同时通信。crossbar NC包含一条地址线和两条数据线。地址线是单向的,从SM到L2 banks,而两条数据线则是双向的,存储SM和L2 banks。因此,通讯是点到点的。一个内存请求队列(memory-request queue, MRQ)和一个bank 加载队列( bank load queue, BLQ)分别对应了一个SM和L2 bank。当load请求从SM中的LSU产生时,它会首先缓存在MRQ里,然后通过NC被分发到目的BLQ中。在BLQ中等待一会,然后这个请求将被L2 banks处理。crossbar network在同时多个连接时有很高的切换代价,特别是当访问请求随机且数据量大。
GPU芯片架构一览
Reference:


最新评论
感谢博主,让我PyTorch入了门!
博主你好,今晚我们下馆子不?
博主,你的博客用的哪家的服务器。
您好,请问您对QNN-MO-PYNQ这个项目有研究吗?想请问如何去训练自己的数据集从而实现新的目标检测呢?
where is the source code ? bomb1 188 2 8 0 0 hello world 0 0 0 0 0 0 1 1 9?5
在安装qemu的过程中,一定在make install 前加入 sudo赋予权限。
所以作者你是训练的tiny-yolov3还是yolov3...
很有用