 LinMao's Blog(林茂的博客)
LinMao's Blog(林茂的博客)Published in ASPLOS'25 by Microsoft
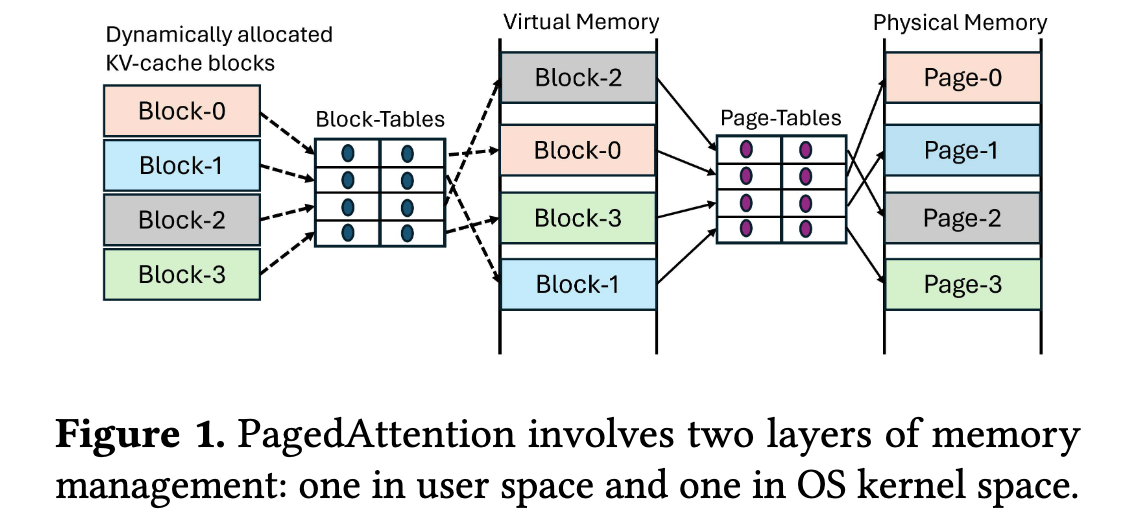
为了保持 KV cache 的内存地址连续,vLLM 里面使用了 Block Table 映射动态分配的 KV cache block 到实际使用 cudaMalloc 申请的内存 block,这些内存需要进一步的通过 GMMU translate 到真正的物理内存。就像图一这样。
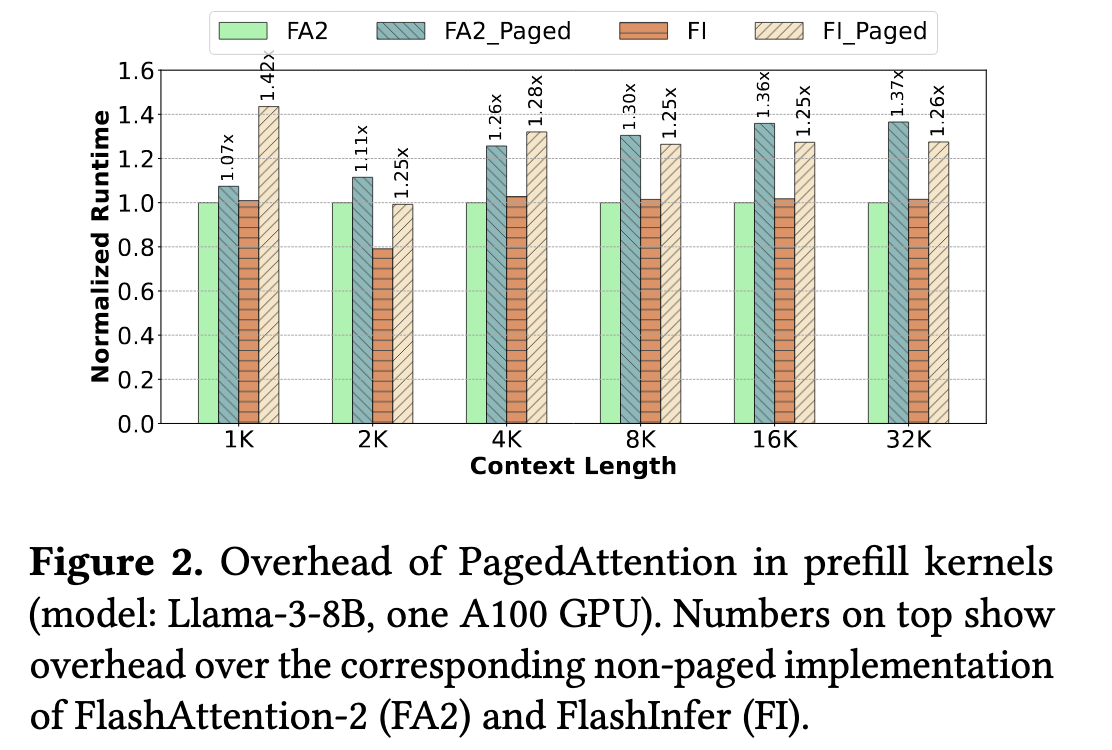
这个过程中,首先需要修改 Kernel,主要是 index offset 的计算,使其好像访问连续的 GPU memory(实际上这些并不连续,只是通过 block table 让他们逻辑上连续起来了),这个过程本身是有 overhead 的,overhead 大概是图二。
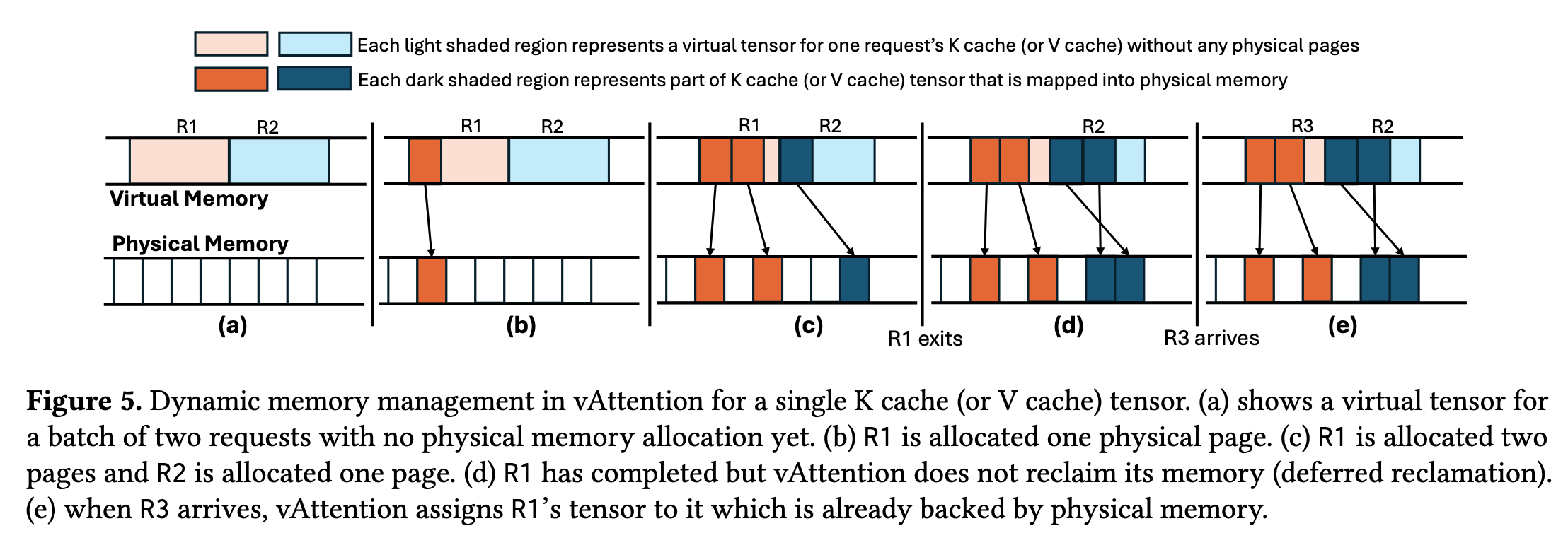
这篇论文提出了一个方法,利用 VMM APIs,对于每个 request 的 KV cache 分配最大的虚拟内存地址,但是并不分配物理的内存空间,物理空间在 LLM serving 的过程中动态地按需分配。如此一来,既可以满足 LLM serving 中对于 KV cache 地址连续的要求,又可以动态按需分配内存还没有像 vLLM 那样的 overhead。然后再加上一些优化,比如 如何保持 mapping,如何调整 page size 来减少 fragmentation 的同时又保证 latency。这个idea上也有点像 GMLake,都是通过内存 API 来映射虚拟到物理的地址,在不违背内存地址连续的语意,同时减少碎片。


最新评论
感谢博主,让我PyTorch入了门!
博主你好,今晚我们下馆子不?
博主,你的博客用的哪家的服务器。
您好,请问您对QNN-MO-PYNQ这个项目有研究吗?想请问如何去训练自己的数据集从而实现新的目标检测呢?
where is the source code ? bomb1 188 2 8 0 0 hello world 0 0 0 0 0 0 1 1 9?5
在安装qemu的过程中,一定在make install 前加入 sudo赋予权限。
所以作者你是训练的tiny-yolov3还是yolov3...
很有用