 LinMao's Blog(林茂的博客)
LinMao's Blog(林茂的博客)
Published in SOSP'23 from UC Berkeley
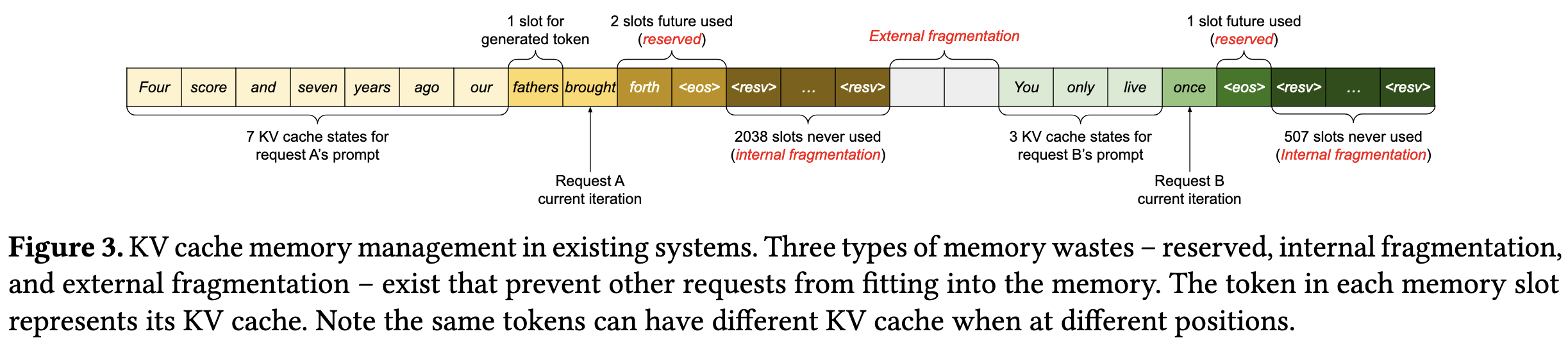
LLM serving 过程中,总是根据之前的 prompt tokens 和 已经生成的 tokens 来预测下一个 token。本质上就是根据所有已知的 tokens (prompt 和已经生成的 tokens)来搜索出下一个最有可能的 token。也就是每次搜索下一个 token,需要知道之前 tokens 的 context,这个 context 就是以 KV cache。所以 LLM serving 中 KV cache 有两个问题:1. 每个 request 的 KV cache 必须连续;2. 每个 request 的 KV cache 大小是未知的。所以一般都是给每个 request 分配最大的 KV cache,并且保证连续。就像图三,这种方式下往往有很大内存浪费,导致同时处理的 request 变少,从而限制了 serving 的吞吐量。
这篇论文提出了 PagedAttention,其实就是复用操作系统中的虚拟内存。核心想法有两个:1. 将连续的 KV cache 分成相同大小的更小块,然后通过一个 block table 来保存从连续的”逻辑“地址到不连续的”物理“地址之间的映射(下面这张图就是这种映射关系),从而实现不连续的内存分配来满足连续的 KV cache 语音;2. 动态分配 KV cache,而不是像以前那样开始就分配最大值。
![]()
这样做能够极大地减少内存碎片和内存浪费,从而能够同时跑多个 request 来提高吞吐量。这个 work 的 idea 巧妙的借用传统操作系统的虚拟内存,还挺有趣;不过感觉这种 block translation 的 overhead 应该很大。


最新评论
感谢博主,让我PyTorch入了门!
博主你好,今晚我们下馆子不?
博主,你的博客用的哪家的服务器。
您好,请问您对QNN-MO-PYNQ这个项目有研究吗?想请问如何去训练自己的数据集从而实现新的目标检测呢?
where is the source code ? bomb1 188 2 8 0 0 hello world 0 0 0 0 0 0 1 1 9?5
在安装qemu的过程中,一定在make install 前加入 sudo赋予权限。
所以作者你是训练的tiny-yolov3还是yolov3...
很有用